K-Means
This is a unsupervised clustering algorithm.
K-Means will group our data into clusters so that it minimizes the sum of squared distances from the centroid of the cluster.
Why is it awesome ? Wikipedia:
k-means clustering in particular when using heuristics such as Lloyd's algorithm is rather easy to implement and apply even on large data sets. As such, it has been successfully used in various topics, including market segmentation, computer vision, geostatistics, astronomy and agriculture. It often is used as a preprocessing step for other algorithms, for example to find a starting configuration.
The article also mentions applications in:
- vector quantization
- cluster analysis
- feature learning
Algorithm
If are data points, and we want to group things into sets , then minimizing the within cluster sum of squares (WCSS) amounts to:
The most popular / common algorithm is called Lloyd's Algorithm, named after Steward P. Lloyd. It requires some type of initialization. The two main initializations, Forgy and Random Parition, are both variations of choosing a random point to be the inital mean for each cluster.
Initalization - pick random points !
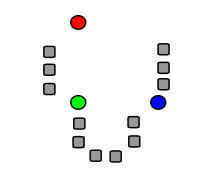
Lloyd's algorithm consists of three steps:
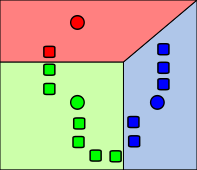
- Assignment (or Expectation) Step
- Assign each point to the cluster whose mean gives the smallest WCSS
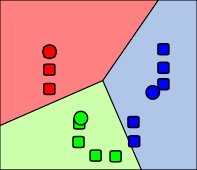
- Update (or Maximization) Step
- Calculate new means

- Iterate
- Repeat until "good enough". That is, centers don't change very much or, more commonly, a certain number of iterations has been reached. Scikit-learn will let you set the number of iterations with
max_iter.
- Repeat until "good enough". That is, centers don't change very much or, more commonly, a certain number of iterations has been reached. Scikit-learn will let you set the number of iterations with
All images are Create Commons from here.
Interactive Demonstration
Naftali Harris has an excellent demo here.